MySQL中的回表和索引覆盖示例详解
索引类型
聚簇索引: 叶子节点存储的是行记录,每个表必须要有至少一个聚簇索引。使用聚簇索引查询会很快,因为可以直接定位到行记录
普通索引:二级索引,除聚簇索引外的索引,即非聚簇索引。普通索引叶子节点存储的是主键(聚簇索引)的值。
聚簇索引递推规则:
- 如果表设置了主键,则主键就是聚簇索引
- 如果表没有主键,则会默认第一个NOT NULL,且唯一(UNIQUE)的列作为聚簇索引
- 以上都没有,则会默认创建一个隐藏的row_id作为聚簇索引
索引结构
id 是主键,所以是聚簇索引,其叶子节点存储的是对应行记录的数据
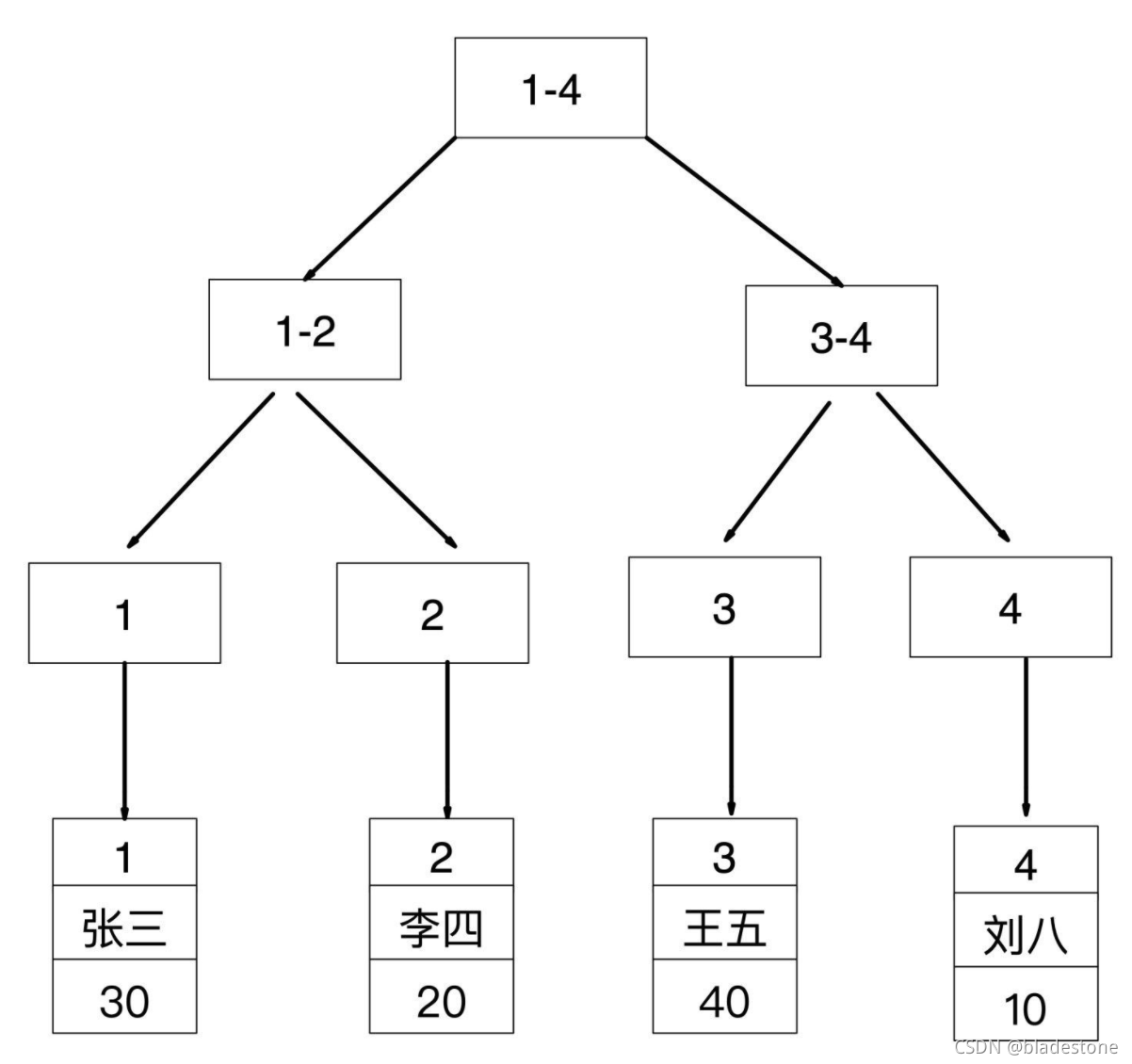
非聚簇索引(Non-ClusteredIndex)

聚簇索引查询
如果查询条件为主键(聚簇索引),则只需扫描一次B+树即可通过聚簇索引定位到要查找的行记录数据。
如:select * from user where id = 1;
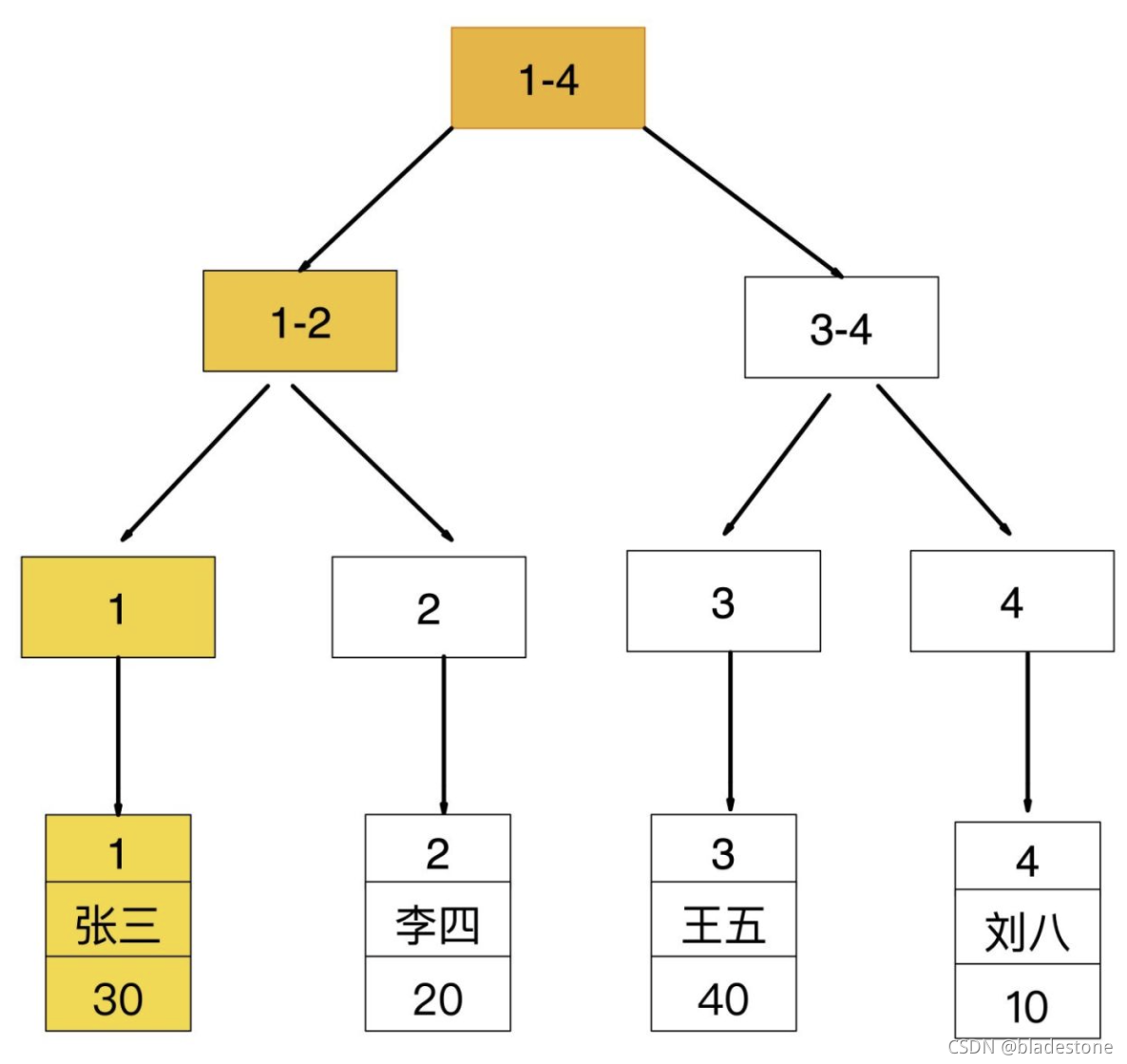
非聚簇索引查询
如果查询条件为普通索引(非聚簇索引),需要扫描两次B+树,第一次扫描通过普通索引定位到聚簇索引的值,然后第二次扫描通过聚簇索引的值定位到要查找的行记录数据。
如:select * from user where age = 30;
1. 先通过普通索引 age=30 定位到主键值 id=1
2. 再通过聚集索引 id=1 定位到行记录数据

先通过普通索引的值定位聚簇索引值,再通过聚簇索引的值定位行记录数据,需要扫描两次索引B+树,它的性能较扫一遍索引树更低。
索引覆盖
只需要在一棵索引树上就能获取SQL所需的所有列数据,无需回表,速度更快。
例如:select id,age from user where age = 10;

使用id,age,name查询:
select id,age,name, salary from user where age = 10;
explain分析:age是普通索引,但name列不在索引树上,所以通过age索引在查询到id和age的值后,需要进行回表再查询name的值。此时的Extra列的Using where表示进行了回表查询
Type: all, 表示全表扫描

增加表的联合索引:CREATE INDEX idx_user_name_age_salary ON mydb.user (name, age, salary);
explain分析:此时字段age和name是组合索引idx_age_name,查询的字段id、age、name的值刚刚都在索引树上,只需扫描一次组合索引B+树即可,这就是实现了索引覆盖,此时的Extra字段为Using index表示使用了索引覆盖。

分页查询(非利用索引):

添加索引之后,即可实现利用索引快速查找。
总结
更多相关文章
- MySQL系列多表连接查询92及99语法示例详解教程
- Android(安卓)- Manifest 文件 详解
- Android的Handler机制详解3_Looper.looper()不会卡死主线程
- Andorid Dialog 示例【慢慢更新】
- Selector、shape详解(一)
- android2.2资源文件详解4--menu文件夹下的菜单定义
- Android(安卓)PureMVC
- Android发送短信方法实例详解
- Ubunu下搭建android NDK环境