老街腾龙娱乐17649117476
datatable-让Python数据分析更快 (101个高频操作)
本文主角:Python的datatable,在一定程度上不乏为pandas有力竞争者,其模仿R中data.table的核心算法和接口,致力于更快的、处理size更大的数据。这里分享datatable的101个常用操作,助快速上手datatable。
0、安装
pip install datatable1、加载datatable、查看版本号
import datatable as dtdt.version2、三种方式创建datatable.Frame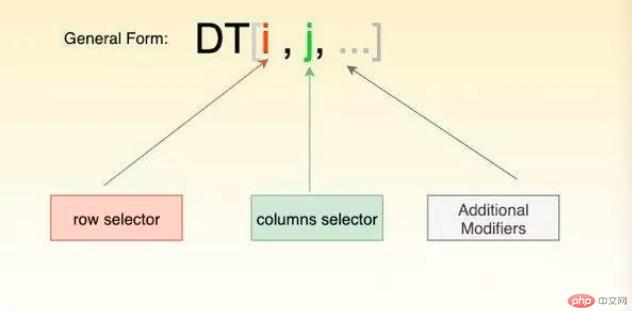
import pandas as pdimport numpy as npimport datatable as dt# Inputsmy_list = list(‘abcedfghijklmnopqrstuvwxyz’)my_arr = np.arange(26)my_df = pd.DataFrame(dict(col1=my_list, col2=my_arr))# Solutiondt_df1 = dt.Frame(my_list) #list创建dt_df2 = dt.Frame(my_arr) #numpy.ndarraydt_df3 = dt.Frame(my_df) #pandas.DataFramedt_df4 = dt.Frame(A=my_arr, B=my_list)
3、读取csv文件为datatable.Frameimport datatable as dtdf = dt.fread(‘https://raw.githubusercontent.com/selva86/datasets/master/BostonHousing.csv')df.head(5)
左下方会默认显示行列数,这是pandas不具有的~
4、 读取csv文件前5行
import datatable as dtdf = dt.fread(‘https://raw.githubusercontent.com/selva86/datasets/master/BostonHousing.csv‘, max_nrows=5)df
5、为datatable.Frame新增一列# Inputimport datatable as dtdf = dt.fread(‘https://raw.githubusercontent.com/selva86/datasets/master/BostonHousing.csv‘, max_nrows=5)# Solutiondf[:, “new_column”] = dt.Frame([1, 2, 3, 4, 5]) #新增一列new_columndf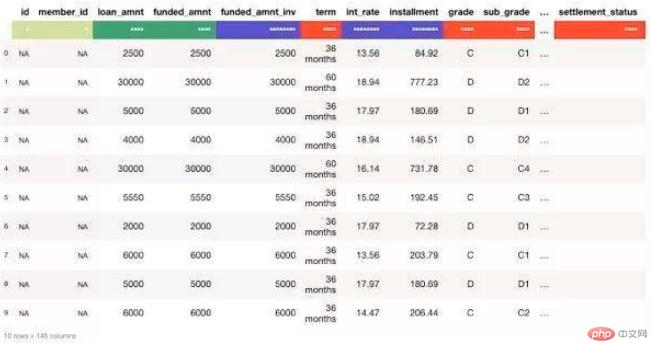
6、取已有列创建新列# Inputimport datatable as dtdf = dt.fread(‘datasets-master/BostonHousing.csv’)# Solutiondf[:, “new_column”] = df[:, dt.f.age + dt.f.rad]df.head()
7、取已有列整数部分创建新列# Inputimport datatable as dtdf = dt.fread(‘datasets-master/BostonHousing.csv’)# Solutiondf[:, “new_column”] = df[:, dt.int32(dt.f.dis)]df.head(5)
8、按条件创建新列import datatable as dtdf = dt.fread(‘datasets-master/BostonHousing.csv’)#age列,年龄大于60赋值old,反之为newdf[:, “new_column”] = dt.Frame(np.where(df[:, dt.f.age > 60], ‘Old’, ‘New’))df.head(5)
9、left join两个datatable.Frameimport datatable as dtdf1 = dt.Frame(A=[1, 2, 3, 4], B=[“a”, “b”, “c”, “d”])df2 = dt.Frame(A=[1, 2, 3, 4, 5], C=[“a2”, “b2”, “c2”, “d2”, “e2”])df2.key = “A”output = df1[:, :, dt.join(df2)]print(df1)print(df2)output
10、修改列名称import datatable as dtdf = dt.fread(‘datasets-master/BostonHousing.csv’)df.names = {‘zn’: ‘zn_new’}df.head(5)
11、每隔1行读取csv文件import datatable as dtimport csvwith open(‘datasets-master/BostonHousing.csv’, ‘r’) as f: reader = csv.reader(f)for i, row in enumerate(reader): row = [[x] for x in row]# 1st rowif i == 0: df = dt.Frame(row) header = [x[0] for x in df[0, :].to_list()] df.names = headerdel df[0, :]# Every 2th rowelif i % 2 == 0: df_temp = dt.Frame(row) df_temp.names = header df.rbind(df_temp)df.head(5)
原始数据
12、读入csv文件按条件修改列
import datatable as dtimport csvwith open(‘datasets-master/BostonHousing.csv’, ‘r’) as f: reader = csv.reader(f)for i, row in enumerate(reader): row = [[x] for x in row]if i == 0: df = dt.Frame(row) header = [x[0] for x in df[0, :].to_list()] df.names = headerdel df[0, :]else: row[13] = [‘High’] if float(row[13][0]) > 25else [‘Low’] # 最后一列大于25赋值High,否则赋值为Low df_temp = dt.Frame(row) df_temp.names = header df.rbind(df_temp)df.head(5)
13、修改特定位置的值import datatable as dtdf = dt.fread(‘datasets-master/BostonHousing.csv’)df[2, 1] = 5df.head(5)
14、datatable.Frame增删操作import datatable as dtdf = dt.fread(‘datasets-master/BostonHousing.csv’)#删除特定位置值del df[2, 1] #删除行del df[3, :]# 删除列del df[:, “chas”]# 按条件删除del df[dt.f.zn == 0, :]df.head(5)
15、datatable.Frame与列表/字典/DataFrame等格式互转import datatable as dtdf = dt.fread(‘datasets-master/BostonHousing.csv’)# to pandas dfpddf = df.to_pandas()# to numpy arraysnp_arrays = df.to_numpy()# to dictionarydic = df.to_dict()# to listlist = df[:,”indus”].tolist()# to tupletuples = df[:,”indus”].to_tuples()# to csv df.to_csv(“BostonHousing.csv”)16、获取datatable.Frame各列数据类型
import datatable as dtdf = dt.fread(‘datasets-master/BostonHousing.csv’)for i in range(len(df.names)): print(df.names[i], “:”, df.stypes[i])
17、datatable.Frame基础统计计算import datatable as dtdf = dt.fread(‘datasets-master/BostonHousing.csv’)df.sum()df.max()df.min()df.mean()df.sd()df.mode()df.nmodal()df.nunique()
18、datatable.Frame中使用group byimport datatable as dtdf = dt.fread(‘datasets-master/Cars93_miss.csv’)df[:, dt.mean(dt.f.Price), dt.by(“Manufacturer”)].head(5)
19、 datatable.Frame按升序sortimport datatable as dtdf = dt.fread(‘datasets-master/Cars93_miss.csv’)# 方法1df.sort(“Price”)# 方法2df[:,:, dt.sort(dt.f.Price)].head(5)
20、 datatable.Frame按降序sortimport datatable as dtdf = dt.fread(‘datasets-master/Cars93_miss.csv’)# Solutiondf[::-1, :, dt.sort(dt.f.Price)].head()
21、数据重复/追加5次import datatable as dtdf = dt.fread(‘datasets-master/Cars93_miss.csv’)# Solutiondt.repeat(df, 5)22、字符串替换
import datatable as dtdf = dt.fread(‘https://raw.githubusercontent.com/selva86/datasets/master/Cars93_miss.csv') Solutiondf.replace(“Audi”, “My Dream Car”)df.head(5)
23、按条件提取值# Inputimport datatable as dtdf = dt.fread(‘datasets-master/Cars93_miss.csv’)# Solution# Get the highest priceprint(“Highest Price : “, df[:, dt.f.Price].max()[0, 0])# Get Manufacturer with highest pricedf[dt.f.Price == df[:, dt.f.Price].max()[0, 0], [‘Manufacturer’, ‘Model’, ‘Type’]]
24、修改列名import datatable as dtdf = dt.fread(‘datasets-master/Cars93_miss.csv’)# Solutionold_col_name = “Model”new_col_name = “Car Model”df.names = [new_col_name if x == old_col_name else x for x in df.names]df.head(5)25、统计每列NA值
import datatable as dtdf = dt.fread(‘datasets-master/Cars93_miss.csv’)# Solutiondf.countna()
26、取一列import datatable as dtdf = dt.fread(‘datasets-master/Cars93_miss.csv’)# Solutiondf[:, “Model”].head(5)27、列顺序颠倒
Inputimport datatable as dtdf = dt.fread(‘datasets-master/Cars93_miss.csv’)# Solution 1df.head()df[:,::-1].head(5)28、格式化输出
import datatable as dtdf = dt.Frame(random=np.random.random(4)**10)df[:, “random2”] = dt.Frame([‘%.6f’ % x for x in df[:, “random”].to_list()[0]])df
29、每隔20行按条件过滤# Inputimport datatable as dtdf = dt.fread(‘https://raw.githubusercontent.com/selva86/datasets/master/Cars93_miss.csv') Solutiondf[::20, [‘Manufacturer’, ‘Model’, ‘Type’]]30、rows颠倒
import datatable as dtdf = dt.fread(‘datasets-master/Cars93_miss.csv’)print(df.head())# Solutiondf[::-1,:]31、按指定值归一化数据
Inputimport datatable as dtdf = dt.fread(“datasets-master/BostonHousing.csv”)# Solutionfor i in df.names: df[:,i] = df[:,(dt.f[i] - df[:,dt.min(dt.f[i])][0,0])/(df[:,dt.max(dt.f[i])][0,0] - df[:,dt.min(dt.f[i])][0,0])]df.head(5)
32、group并取均值生成新列# Inputimport datatable as dtdf = dt.Frame(fruit=[‘apple’, ‘banana’, ‘orange’] * 3, rating=np.random.rand(9), price=np.random.randint(0, 15, 9))df[:, dt.mean(dt.f.price), dt.by(“fruit”)]
33、按两列join# Inputimport datatable as dtdf1 = dt.Frame(A=[1, 2, 3, 4], B=[“a”, “b”, “c”, “d”], D=[1, 2, 3, 4])df2 = dt.Frame(A=[1, 2, 4, 5], B=[“a”, “b”, “d”, “e”], C=[“a2”, “b2”, “d2”, “e2”])# Solutiondf2.key = [“A”, “B”]output = df1[:, :, dt.join(df2)]output
34、ML小案例import datatable as dtfrom datatable.models import Ftrl# Import datatrain_df = dt.fread(‘pima_indian_diabetes_training_data.csv’)test_df = dt.fread(‘pima_indian_diabetes_testing_data.csv’)# Create Ftrl modelftrl_model = Ftrl()# add parameter values while creating modelftrl_model = Ftrl(alpha=0.1, lambda1=0.5, lambda2=0.6)# change paramter of existing modelftrl_model.alpha = 0.1ftrl_model.lambda1 = 0.5ftrl_model.lambda2 = 0.6# Prepare training and test datasettrain_df[:, “diabetes”] = dt.Frame( np.where(train_df[:, dt.f[“diabetes”] == “pos”], 1, 0))test_df[:, “diabetes”] = dt.Frame( np.where(test_df[:, dt.f[“diabetes”] == “pos”], 1, 0))x_train = train_df[:, [“pregnant”, “glucose”, “pressure”, “mass”, “pedigree”, “age”]]y_train = train_df[:, [“diabetes”]]x_test = test_df[:, [“pregnant”, “glucose”, “pressure”, “mass”, “pedigree”, “age”]]y_test = test_df[:, [“diabetes”]]# training the modelftrl_model.fit(x_train, y_train)# predictions of the modeltargets = ftrl_model.predict(x_test)print(targets.head(5))# feature importancefi = ftrl_model.feature_importancesfiREF:https://www.machinelearningplus.com/data-manipulation/101-python-datatable-exercises-pydatatable/
更多相关文章
- Android(安卓)Activity 切屏处理
- Android(安卓)MTP之服务端UsbService启动
- Android中的Handler、Looper、Message简要分析
- 使用eclipse创建android工程时得到警告
- [Android] 无法创建项目问题解决
- android的文件读写
- android NDK/JNI-实例开发流程
- Android(安卓)图片设置圆角
- 了解使用Android(安卓)ConstraintLayout