newtype_Haskell笔记8
一.ZipList与List
在List场景,xs <*> ys表示从左侧xs中取出函数作用于右侧ys中的每一项,有两种实现方式:
笛卡尔积
拉链式的一一结对
分别对应[]和ZipList,例如:
import Control.Applicative;-- 笛卡尔积> [(+2), (*2), (/2)] <*> [1, 2, 3][3.0,4.0,5.0,2.0,4.0,6.0,0.5,1.0,1.5]-- 拉链式结对> getZipList $ ZipList [(+2), (*2)] <*> ZipList [1..][3,4]笛卡尔积只能用于有限长度List,而拉链式结对还适用于无限长List的场景。对<*>而言,这两种实现都是可取的,但[]无法同时拥有两种不同的Applicative实现,所以造出了ZipList,让它以拉链结对的方式实现Applicative
P.S.这里提到的<*>是Applicative类定义的行为,具体见Functor与Applicative_Haskell笔记7
二.newtype
ZipList就是因这个场景而产生的,本质上是对List的包装,定义如下:
newtype ZipList a = ZipList { getZipList :: [a] } deriving ( Show, Eq, Ord, Read, Functor , Foldable, Generic, Generic1)(摘自Control.Applicative)
通过newtype关键字,基于现有类型([])创建一个新的(ZipList),再重写其接口实现:
instance Applicative ZipList where pure x = ZipList (repeat x) liftA2 f (ZipList xs) (ZipList ys) = ZipList (zipWith f xs ys)P.S.这里只实现了liftA2,而没有出现<*>,是因为Applicative有最小完整定义(minimal complete definition)约束:
A minimal complete definition must include implementations of pure and of either <*> or liftA2. If it defines both, then they must behave the same as their default definitions:(<*>) = liftA2 id liftA2 f x y = f <$> x <*> y预先定义了这两个函数的关联,所以择其一实现即可(根据关联关系能够自动生成另一个)
那么,newtype到底做了什么?
实际上,newtype所做的事情只是创建新类型,把现有类型包装起来
在类似的场景下,JS的话,我们会这么做:
class ThisType { constructor(value) { this.value = value; } ['<*>']() { console.log('笛卡尔积'); }};class ThatType { constructor(...args) { this.originalValue = new ThisType(...args); } getOriginalType() { return this.originalValue; } ['<*>']() { console.log('拉链结对'); }};// testlet thisOne = new ThisType(1);thisOne['<*>'](); // 笛卡尔积console.log(thisOne); // ThisType {value: 1}let thatOne = new ThatType(2);thatOne['<*>'](); // 拉链结对console.log(thatOne.getOriginalType()); // ThisType {value: 2}创建新类型(ThatType),把原类型(ThisType)包起来,提供不同的<*>实现
二者只是简单的依赖,并没有继承关系,所以通过newtype创建的类型并不自动具有原类型的所有方法(也不会自动获得原类型所实现的typeclass)。就类型而言,二者是完全独立的不同类型,所以:
> [3] ++ [1, 2][3,1,2]> type IntList = [Int]> [3] ++ ([1, 2] :: IntList)[3,1,2]> (ZipList [3]) ++ (ZipList [1, 2])<interactive>:109:1: error:• Couldn't match expected type ‘[a]’ with actual type ‘ZipList Integer’• In the first argument of ‘(++)’, namely ‘ZipList [3]’...不像type创建的别名类型可以与原类型等价换用,newtype创建的新类型与原类型是完全不同的东西,唯一的联系是新类型内部实际操作的是原类型(通过持有原类型实例引用),通过这种方式在外层实现对原类型的扩展/增强
语法要求
从语法作用来看,newtype与data一样,都用来创建新类型,但newtype限制更多:
data can only be replaced with newtype if the type has exactly one constructor with exactly one field inside it.要求newtype声明的类型只能有一个值构造器,并且这个值构造器只能有一个参数(field)。除此之外,就与data关键字没什么区别了
P.S.关于值构造器与参数,见类型_Haskell笔记3
三.对比type和data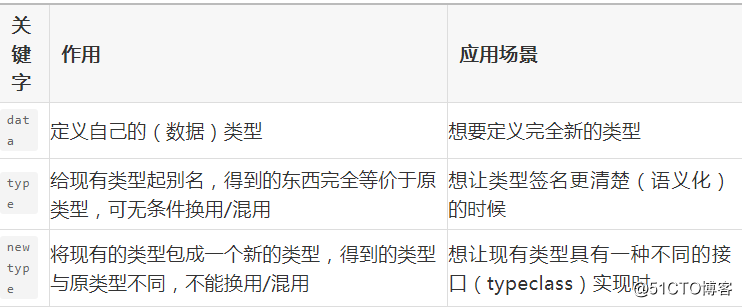
四.newtype与惰性计算
Haskell中大多数计算都是惰性的(少数指的是foldl'、Data.ByteString之类的严格版本),也就是说,计算只在不得不算的时候才会发生
惰性计算一般看起来都很符合直觉(不需要算的就先不算),但特殊的是,类型相关的场景存在隐式计算(不很符合直觉)
undefined
undefined表示会造成错误的计算:
> undefined*** Exception: Prelude.undefinedCallStack (from HasCallStack): error, called at libraries/base/GHC/Err.hs:79:14 in base:GHC.Err undefined, called at <interactive>:12:1 in interactive:Ghci1能够用来检验惰性(计算到底执行了没),例如:
> head [1, undefined, 3, undefined, undefined]1> let (a, _) = (1, undefined) in a + 12特殊地,函数调用时的模式匹配本身是需要计算的,不管匹配结果是否需要用到,例如:
sayHello (_, _) = "hoho"> sayHello undefined"*** Exception: Prelude.undefinedCallStack (from HasCallStack): error, called at libraries/base/GHC/Err.hs:79:14 in base:GHC.Err undefined, called at <interactive>:37:10 in interactive:Ghci17而下面这种形式的就不会被计算:
sayHello _ = "hoho"> sayHello undefined"hoho"二者的差异在于,对于前者,需要做一些基本的计算来看看应该用Tuple的哪个值构造器,后者则不需要
但奇怪的是,Tuple明明只有一个值构造器(不需要“看应该用Tuple的哪个值构造器”):
data () = ()我们知道没必要去检查应该用Tuple的哪个值构造器,但Haskell不知道,因为按照约定,data关键字定义的数据类型可以有多个值构造器,即便只声明了一个,它也要找过才知道。那么,想到了什么?
newtype。它明确约定了只有一个值构造器(并且这个值构造器只有一个参数),不妨试一下:
newtype MyTuple a b = MyTuple {getTuple :: (a, b)}> sayHello (MyTuple _) = "hh"> sayHello undefined"hh"确实如此,Haskell足够聪明,明确知道不存在多个值构造器时,不再做无谓的计算
参考资料
48 newtype
Newtype
更多相关文章
- Spring IoC 依赖注入(支持哪些数据类型?)
- c语言数据类型(初学)
- pgsql 修改字段类型为json
- MyBatis之Mapper XML 文件详解(四)-JDBC 类型和嵌套查询
- BigDecima类型数据的处理--Non-terminating decimal expansio
- 五分钟学会java中的基础类型封装类
- 面试必问:String类型为什么设计成不可变的?
- 服务端开发指南与最佳实战 | 数据存储技术 | MySQL(01)数据类型的
- 基本类型转 String