临摹源码 | 一比一手写Dubbo源码中的SPI(内附git地址)
前言
之前对dubbo的SPI进行了四篇的分享.大家对这个概念有了一些初步的了解.谈到编程水平如何进阶,大家可能都会异口同声的说出三个字,看源码.但是我却始终认为,编程光看,是永远学不会的.但是很多时候,连怎么看源码都无从下手,你叫我写仿写源码,这不是开玩笑?

我们可以回忆一下我们在公司是怎么写代码的.首先产品提出需求,接着开需求评审会,再接着代码设计,最后开始编码.
今天我们就仿造这个流程,自己动手实现dubbo的spi
提出需求
在 dubbo源码解析-spi(二) 中,我们已经分析了dubbo中spi和jdk中spi有什么区别,dubbo相比jdk变化的内容大致如下:
(一) 拓展点增加了缓存,提高了性能
(二) 增加了spi的默认值
(三) 增加了通过key的形式获取拓展点
(四) 增加了Ioc和AOP功能
这里插句题外话,我们不能为了看源码而看源码,最重要的是,在看源码的过程中,学会分析问题的思路.假如有个新的RPC框架,比如肥朝RPC,我问你肥朝RPC中的SPI和JDK的SPI有几点区别呢?我在
dubbo源码解析-spi(二)这篇中,就把我是如何分析出这四点的整个心路历程展示出来,你可以大胆走进我的内心世界.
需求评审
既然是需求评审,其实说白了,就是和产品砍需求.产品提出的需求就是上面那四个功能.(一)(二)(三)都是基本又比较核心的功能,这些砍了那这个版本就没意思了,(四)这个可以放在下一个版本去迭代开发.
代码设计
只要实现了key-value获取拓展点,那么获取默认拓展点就很容易了,因为这个默认拓展点只是key-value的一种特殊形式,他的默认值,也就是这个key,就在SPI注解上.其实思路总起起来就一句话,因为我们在拓展点配置文件里面已经配置了实现类的权限定名.首先我们把这些配置文件全部加载出来,解析出全限定名,缓存起来.然后你要获取具体的拓展点,我就在缓存中把他的权限定名拿出来,反射实例化成一个对象返回回去.也就是1.读取并解析文件内容 2.放入map缓存 3.反射生成对象.这三个知识点,我相信看这篇文章的,没有人不会.
按照上面的分析,把代码写出来不难吧.什么,写不出?那往下看
编码
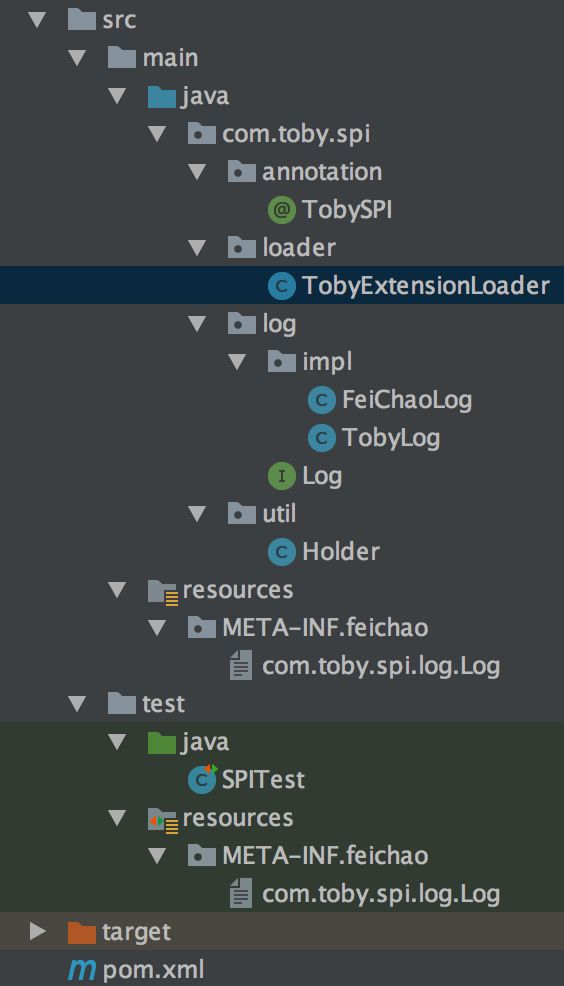
项目结构如图:
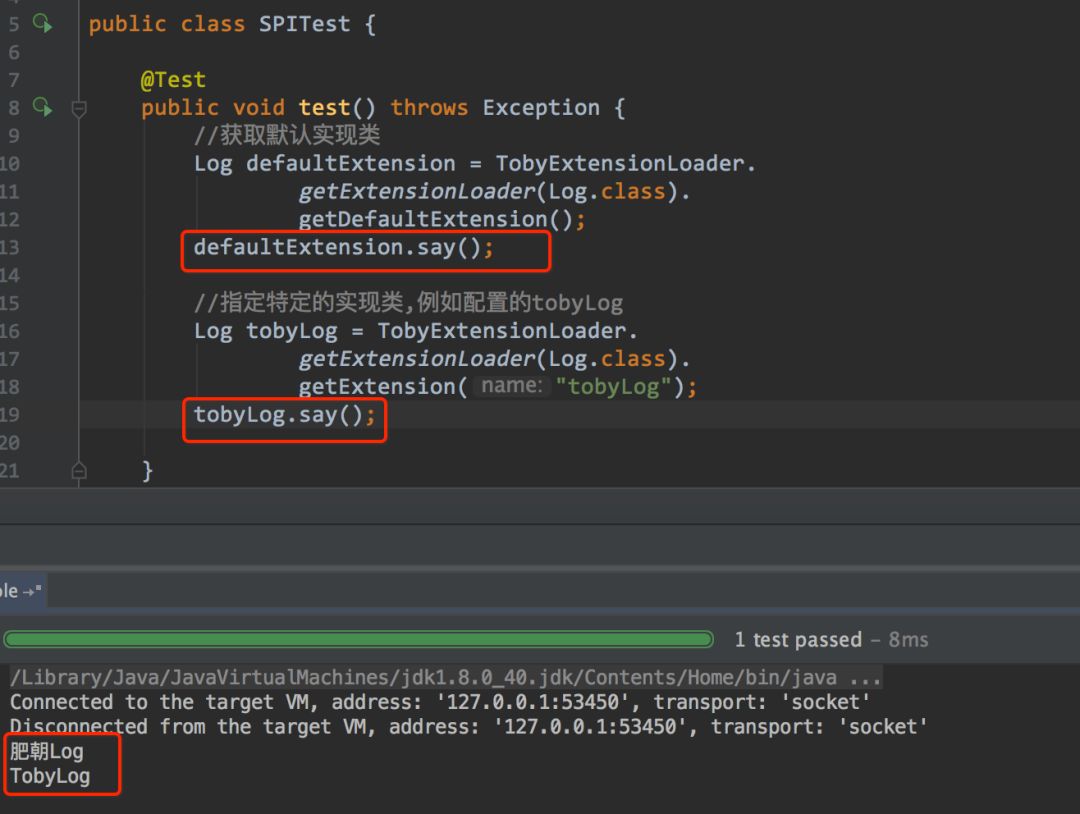
运行结果如图
代码已经上传到码云.可以下载跑起来,本来想用时序图,流程图和大家把思路理一下的,但是弄了几个小时,我觉得还不如自己看代码清楚.核心代码代码不到300行.有问题可以留言.
地址: https://gitee.com/HelloToby/tobySPI
小提示
因为之前部分同学反馈对源码中的思路还不是很清晰.所以这次我就直接把源码中的功能模块抽成一个demo,然后大家先把demo运行起来,接着把demo里面的代码重复写个一两遍.因为demo和源码一比一高仿的(变量名,方法名甚至if换不换行都尽量一致了).所以这个时候,再去看源码就和看自己写的代码应该一样的.这样思路就清晰很多了.希望这个方式对你阅读源码有帮助.
写在最后
关注肥朝公众号,后续还会有更多奇巧淫技,真实企业场景源码级实战和大家分享.让"原理"不再只是面试装逼.也欢迎大家留言一起交流精进
更多相关文章
- spring aop源码分析
- SpringMVC源码分析:一个request请求的完整流程和各组件介绍
- 桥接模式在开源代码中的应用
- 如何写高质量的代码(完结)
- 模板方法模式在开源代码中应用
- 接了烂代码的项目,怎么玩好?
- ConcurrentHashMap基于JDK1.8源码剖析
- 组合模式在开源代码中的应用
- Thread源码剖析