实时数仓|架构设计与技术选型
前言
当我们做一个项目时往往都需要选择该用什么技术。这一部分不是我们普通员工想的,而是架构师会根据客户的需求选择出合适的技术。当选择合适的技术会让我们的开发事半功倍。下面我就来讲解下我做的项目(实时数仓)是如何进行选型的。
一、技术选型
当我们在选择技术时需要根据客户的需求来进行选择。比如:实时统计交易金额(要求延迟不能超过一秒),这时我们在选择技术时就不能用那些批处理的技术比如Hive,MapRducer 等,因为MapRducer 启动有可能就能超过了一秒钟,所以根本就不能满足这些需求。这时我们可以考虑用一些实时计算的技术如 Flink,SparkStreaming等。接下来我们就来讲解下如何选择。
目前市场是有很多实时计算的技术如:Spark streaming、Struct streaming、Storm 、JStorm(阿里) 、Kafka Streaming 、Flink 等众多的技术栈我们该如何选择那?
当我们在选择技术时需要全面考虑,并不是你喜欢这个技术就要用这个技术,这不是明智的选择。企业一般根据 公司员工的技术基础、流行 、技术复用、场景等众多的因素来进行选择。附上一张技术图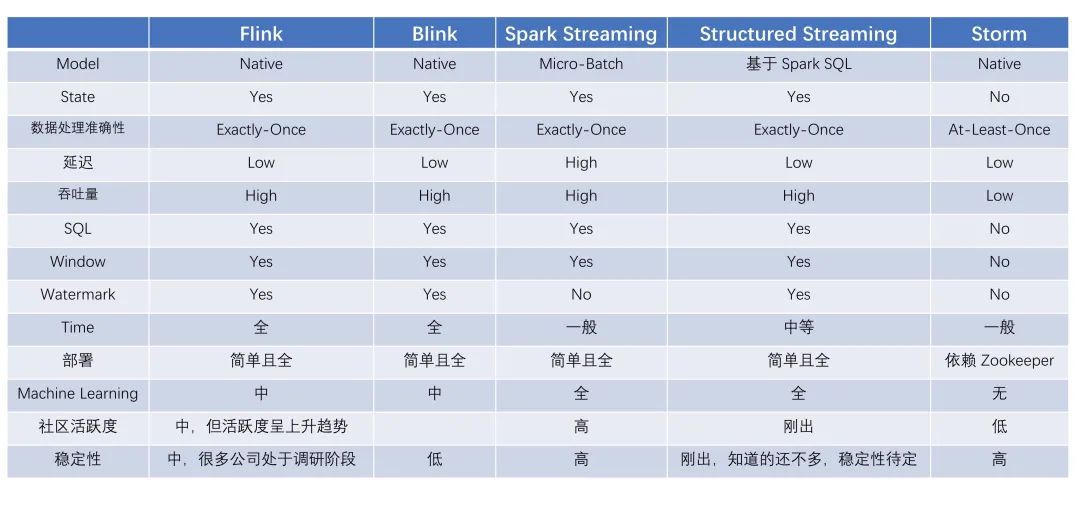 根据上述图片就可以清晰的分析出该用什么技术。我在这里也推荐一下
根据上述图片就可以清晰的分析出该用什么技术。我在这里也推荐一下仅供参考
如果对延迟要求不高的情况下,可以使用 Spark Streaming,它拥有丰富的高级 API,使用简单,并且 Spark 生态也比较成熟,吞吐量大,部署简单,社区活跃度较高,从 GitHub 的 star 数量也可以看得出来现在公司用 Spark 还是居多的,并且在新版本还引入了 Structured Streaming,这也会让 Spark 的体系更加完善。
如果对延迟性要求非常高的话,可以使用当下最火的流处理框架 Flink,采用原生的流处理系统,保证了低延迟性,在 API 和容错性方面做的也比较完善,使用和部署相对来说也是比较简单的,加上国内阿里贡献的 Blink,相信接下来 Flink 的功能将会更加完善,发展也会更加好,社区问题的响应速度也是非常快的,另外还有专门的钉钉大群和中文列表供大家提问,每周还会有专家进行直播讲解和答疑。
本项目:使用Flink来搭建实时计算平台
二、需求分析
目前需求有最后通过报表实时展示:
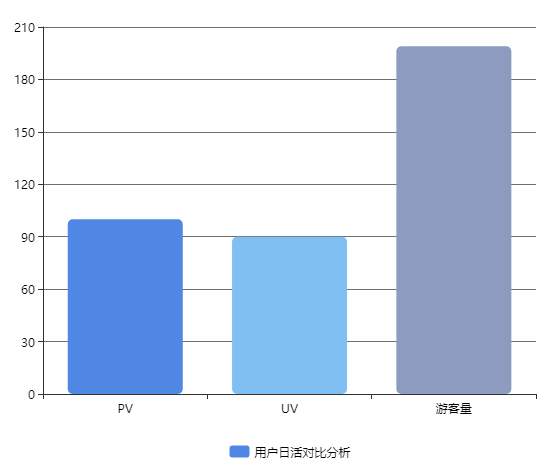
统计用户日活对比分析(PV、UV、游客数)分别使用柱状图显示
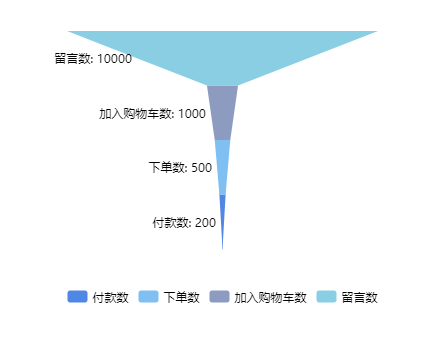
2. 漏斗展示(付款数、下单数、加入购物车数、浏览数)
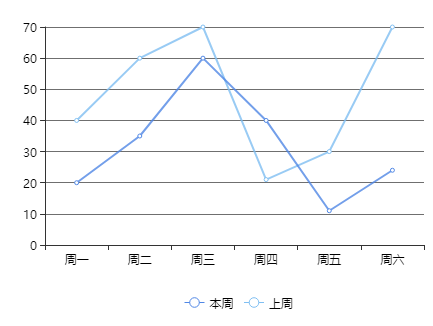
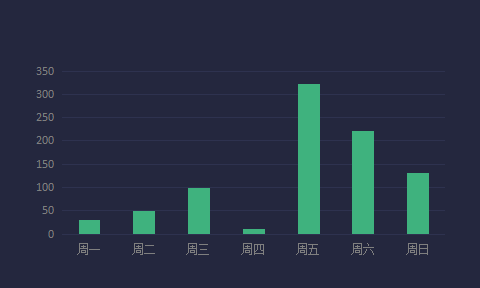
3. 统计一周销售额,使用曲线图显示
 4. 24小时销售曲线图显示
4. 24小时销售曲线图显示
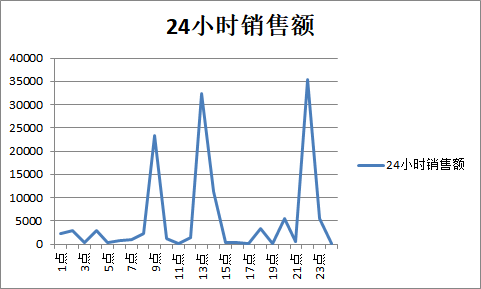
5. 订单状态占比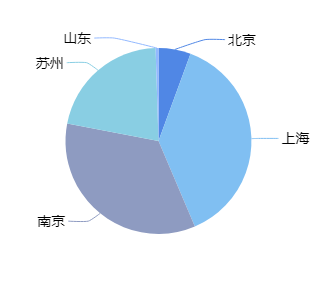 6. 订单完成状态分析
6. 订单完成状态分析
7. TopN地区排行

数据来源PV/UV数据来源
- 来自于页面埋点数据,将用户访问数据发送到web服务器
- web服务器直接将该部分数据写入到kafka的click_log topic 中
销售金额与订单量数据来源
- 订单数据来源于mysql
- 订单数据来自binlog日志,通过canal 实时将数据写入到kafka的order的topic中
购物车数据和评论数据
- 购物车数据一般不会直接操作mysql,通过客户端程序写入到kafka(消息队列)中
- 评论数据也是通过客户端程序写入kafka(消息队列)中
三、架构设计
根据分析需求我们可以这样设计我们架构。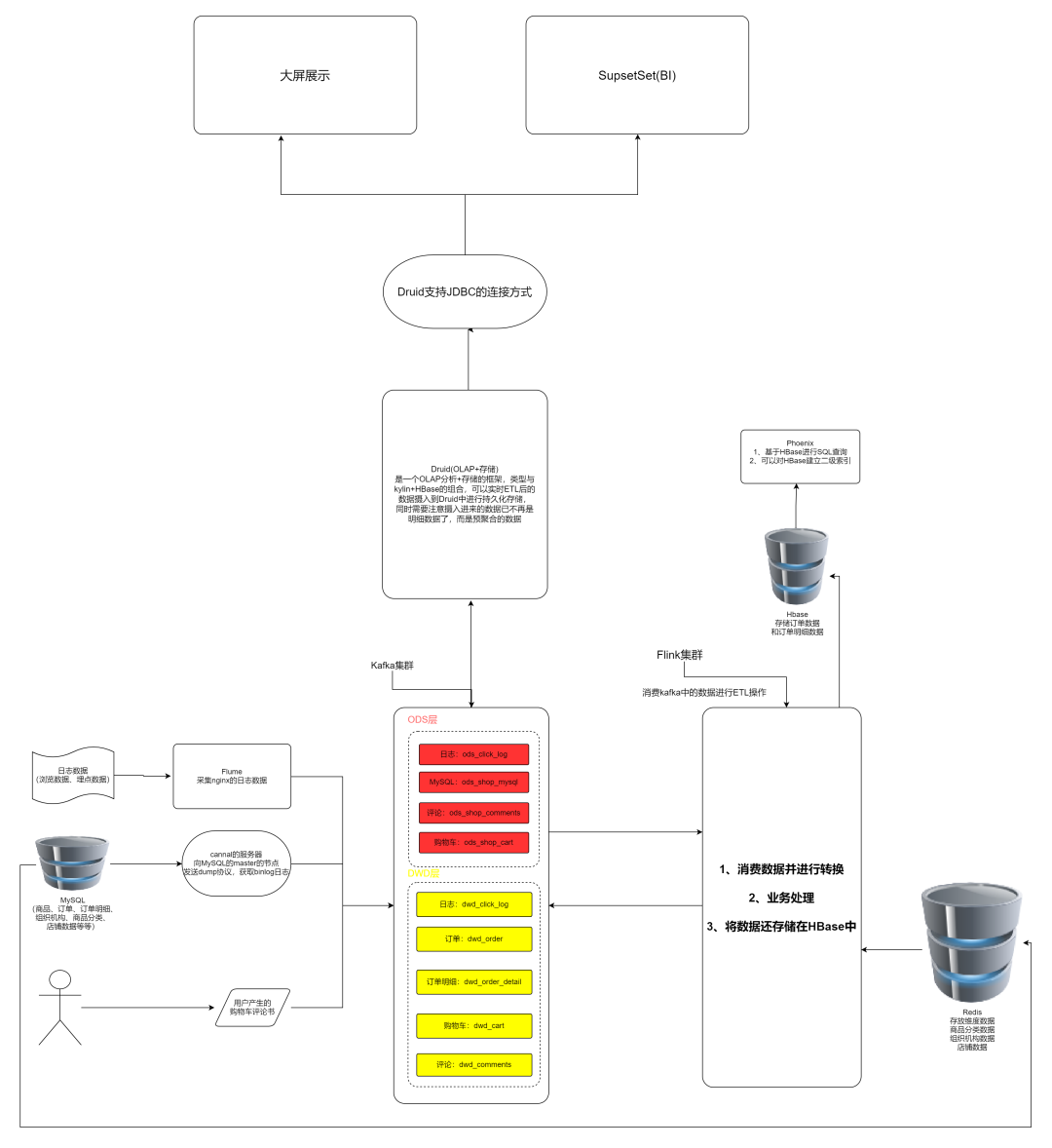 在线架构图:https://gitmind.cn/app/flowchart/43aa8334090bdd1e1074271f08328e25
在线架构图:https://gitmind.cn/app/flowchart/43aa8334090bdd1e1074271f08328e25
小结
本篇文章主要讲解了如何选择一合适技术栈,以及后面分享的技术实时数仓的架构图。我们在离线数仓使用的是hive我们可以在Hive中进行一个层,而要做实时数仓的话需要使用消息队列来做分层,本次项目使用Kafka来分层。我在这里为大家提供大数据的资源需要的朋友可以去下面GitHub去下载,信自己,努力和汗水总会能得到回报的。我是大数据老哥,我们下期见~~~
资源获取 获取Flink面试题,Spark面试题,程序员必备软件,hive面试题,Hadoop面试题,Docker面试题,简历模板等资源请去GitHub自行下载 https://github.com/lhh2002/Framework-Of-BigDataGitee 自行下载 https://gitee.com/li_hey_hey/dashboard/projects实时数仓代码GitHub:https://github.com/lhh2002/Real_Time_Data_WareHouse
更多相关文章
- 数据结构--时间复杂度与空间复杂度
- Java 为什么需要保留基本数据类型
- 不同类型业务系统技术架构的差异化
- 数据库-关系代数
- 数据库-范式
- 数据库数据完整性
- 数据库-事务处理
- 数据库密码配置项都不加密?心也太大了!
- 数据库界的 Swagger,一键自动生成 Java 实体类和数据库文档!不讲武